Alert triage
Group symptoms, suppress duplicate noise, and rank what deserves human attention first.
Agentic operations for on-call teams
Investigate incidents with an AI site reliability engineer that reads logs, metrics, traces, errors, deployments, and runbooks before your team loses the thread.
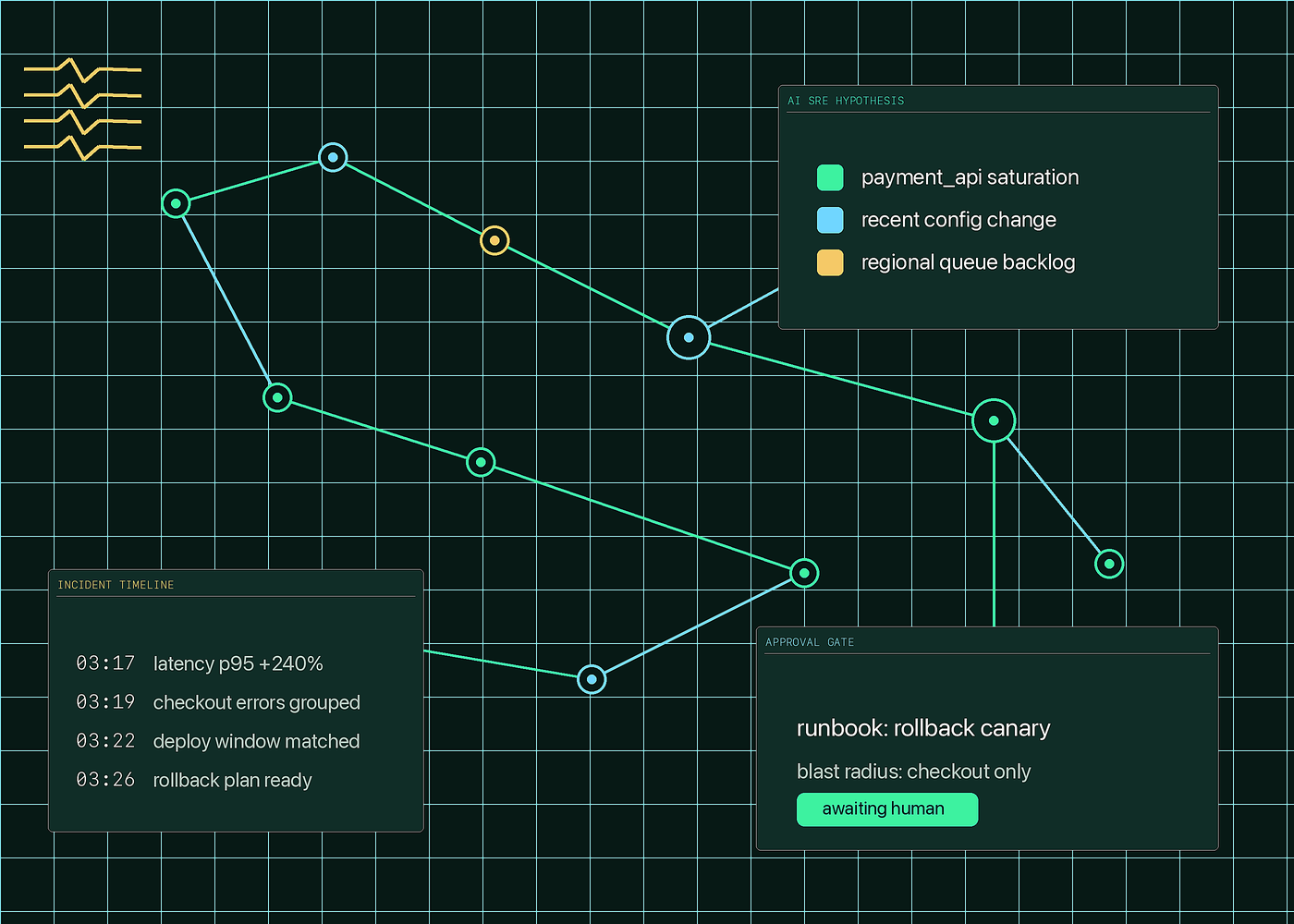
Why AI SRE
Alerts rarely explain themselves. The useful evidence lives across observability tools, deploy history, ticket systems, chat threads, and tribal knowledge. AI SRE compresses that search into a guided investigation.
Group symptoms, suppress duplicate noise, and rank what deserves human attention first.
Correlate changes, error bursts, slow traces, saturation, and deployment windows into testable hypotheses.
Turn incident timelines, approvals, and decisions into searchable context for the next outage.
Workflow
The AI SRE agent should work beside the on-call engineer: gather evidence, explain uncertainty, recommend next steps, and wait for approval before anything changes.
Read the page, service ownership, recent deploys, symptoms, and linked observability signals.
Compare logs, traces, metrics, errors, and infrastructure state to propose likely failure modes.
Surface the blast radius, confidence, rollback plan, and exact command or runbook step.
Generate an incident timeline, handoff summary, postmortem draft, and follow-up tickets.
Capabilities
Ask operational questions and get scoped charts, logs, traces, and event timelines back.
Understand dependencies, upstream failures, saturation, and latency propagation across services.
Work inside Slack, Teams, Claude Code, or MCP-powered workflows where incidents already happen.
Prepare safe commands and playbook steps with explicit approvals, prechecks, and rollback notes.
Create follow-up issues, owner assignments, and suggested fixes when the evidence is strong enough.
Summarize what happened, what changed, who approved actions, and which safeguards are missing.
Trust model
The best AI SRE workflow is fast, but not reckless. Keep humans in charge of production changes, require audit trails, and make the model show why it believes a hypothesis.
FAQ
AI SRE is an agentic reliability workflow that helps teams investigate incidents, reason over observability data, and prepare operational actions for human approval.
No. The practical model is a copilot for on-call engineers: it gathers context, explains evidence, and reduces toil while humans retain production authority.
Start with logs, metrics, traces, error tracking, deployment events, service ownership, runbooks, ticketing, and incident chat history.
Track time to acknowledge, time to useful hypothesis, time to mitigation, duplicate alert reduction, and postmortem follow-through.
Build the operating model